
Method for cross-age face recognition based on identity-age sharing features
-
摘要:
从人脸特征中剔除年龄相关特征,获得纯粹的身份特征,是实现跨年龄人脸识别的重要手段;然而,主流的身份特征提取方法忽略了对身份-年龄共享特征的处理,导致提取到的身份特征不完整。为此,提出引入身份-年龄共享特征的新方法,将混合人脸特征解耦为纯年龄相关特征、纯身份相关特征以及身份-年龄共享特征,然后将纯身份相关特征和身份-年龄共享特征进行多维耦合,从而得到完整的身份特征,有效提高跨年龄人脸识别的准确率。在人脸老化基准数据集Age-DB30上本文方法的识别准确率达到了97.07%,在LFW数据集上达到了99.73%的识别准确率,证明了所提方法的有效性与先进性。
Abstract:Removing age-related features from face features to obtain pure identity features is an important means to achieve cross-age face recognition. However, the mainstream identity feature extraction methods ignore the processing of identity-age sharing features, resulting in incomplete extracted identity features. To this end, a new method of introducing identity-age sharing features was proposed, decoupling mixed face features into pure age-related features, pure identity-related features and identity-age sharing features, and then multi-dimensional coupling of pure identity-related features and identity-age sharing features to obtain complete identity features and effectively improving the accuracy of cross-age face recognition. The proposed method achieved a recognition accuracy of 97.07% on the face aging benchmark dataset Age-DB30 and 99.73% on the LFW dataset, demonstrating the effectiveness and advancedness of the proposed method.
-
Keywords:
- face recognition /
- age invariant /
- transformation /
- canonical correlation analysis
-
引言
得益于近些年来深度学习技术的快速发展和各种大规模训练数据的公开[1-3],人脸识别[4-5]技术取得了令人瞩目的成果。然而,在长期失踪儿童寻找、犯罪嫌疑人监控等领域,跨年龄人脸识别(age-invariant face recognition, AIFR)所面临的人脸变异大、识别精度不足、光学图像质量不佳等突出问题,成为当前人脸识别研究的重要挑战。
目前,跨年龄人脸识别的策略可大致分为基于生成模型和鉴别模型两种类别。生成模型的核心思想是对年龄变化进行建模,如使用基于生成对抗网络[6-7]的模型,利用原始人脸图像生成特定年龄组的高质量图像,以实现跨年龄人脸识别。生成模型往往存在计算量大、模型不稳定等缺点。相比之下,越来越多的研究关注于鉴别模型的改进,利用隐藏因子分析方法可以从混合人脸特征中去除年龄因子,提取具有鲁棒性的身份特征[8]。采用去相关性对抗学习算法(decorrelated adversarial learning,DAL)能够建立成对特征的相关性,以对抗的方式降低成对特征之间的潜在联系[9]。采用多任务学习框架(multi-task learning framework,MTLF),基于注意机制可以在高级语义空间中分离年龄特征,保留更多的身份信息[10]。上述研究假定年龄特征和身份特征,可以使用线性分离方式完美解耦,没有充分考虑由于年龄特征和身份特征共有而难以分割的信息,从而制约了跨年龄识别准确率的进一步提升。
本文提出一种新的深度特征解耦−耦合学习框架,用于跨年龄人脸识别任务, 引进共享特征(identity-age sharing features, ISF)来补充身份特征。通过对混合人脸特征的解耦和对身份相关特征的耦合,获取完整的身份特征,进一步提高跨年龄人脸识别的准确率。
1 所提算法
1.1 基于身份-年龄共享特征的跨年龄人脸识别模型
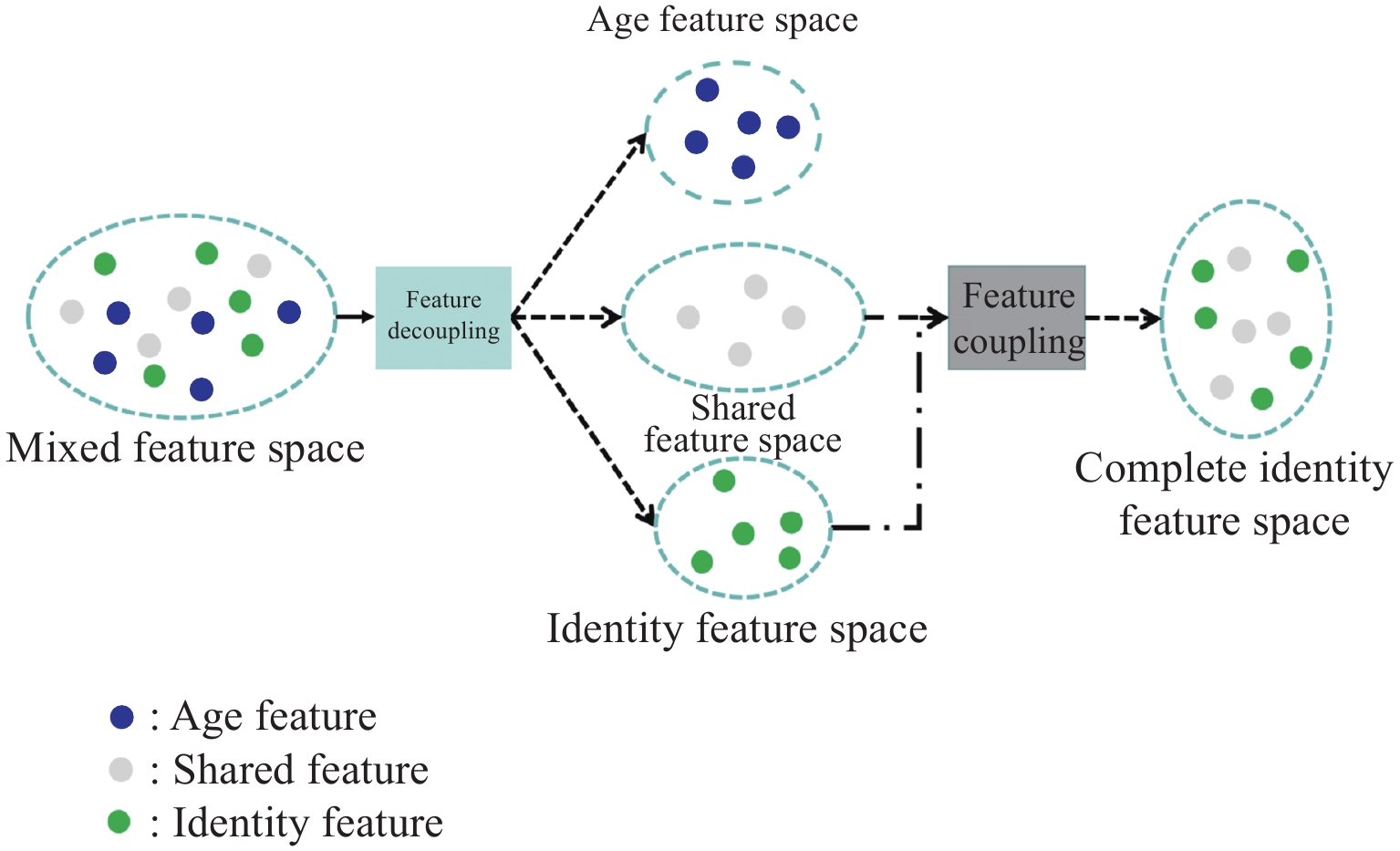
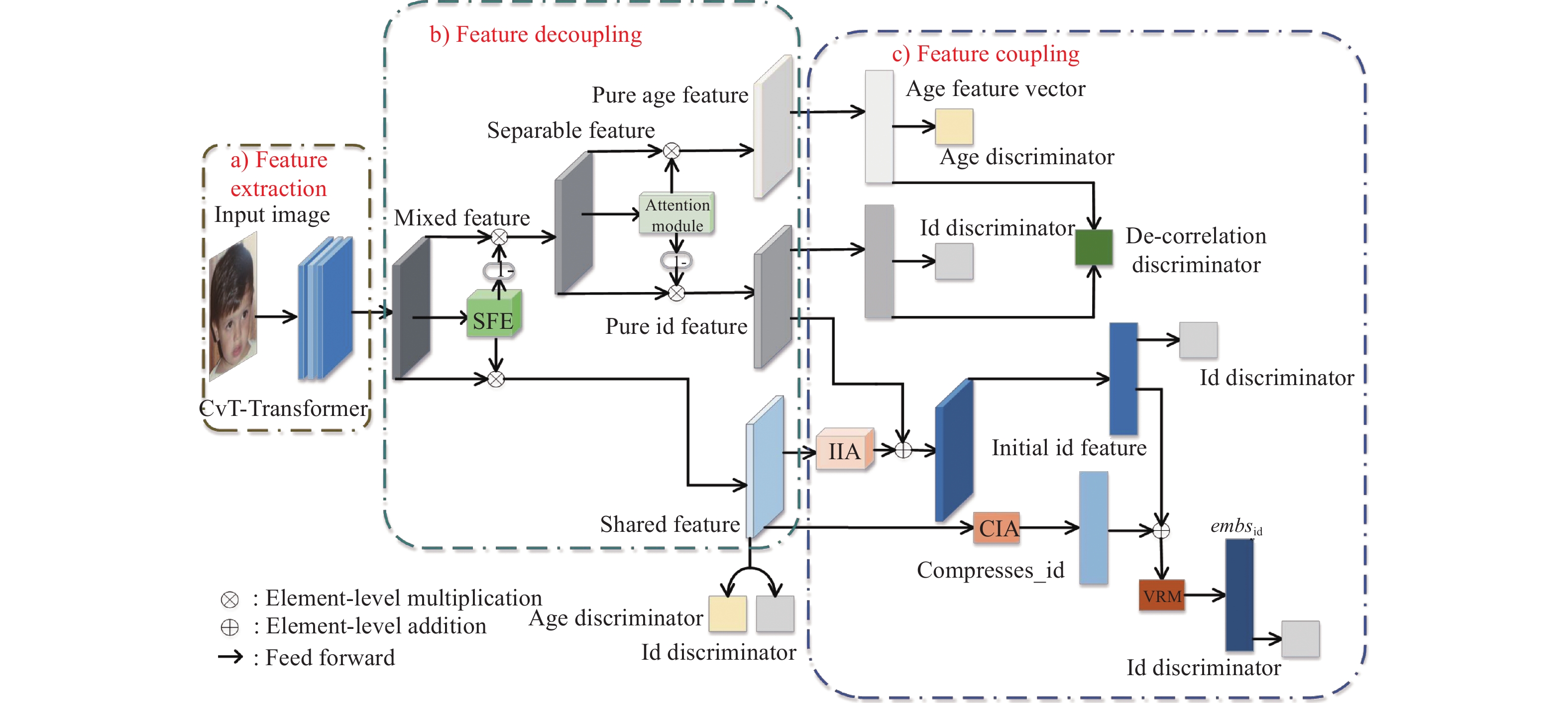
解决跨年龄人脸识别问题的核心在于提取到不受年龄信息干扰的身份特征。本文提出的跨年龄人脸识别模型框架如图1所示,主要分为3个模块:混合人脸特征提取模块、特征解耦模块、特征耦合模块。首先对输入的人脸图像进行面部表征提取,得到混合特征;然后使用特征解耦模块将混合特征解耦为纯年龄相关特征、纯身份相关特征、以及共享特征;利用特征耦合模块,将对人脸识别有用的纯身份相关特征和共享特征在多个维度上进行耦合,得到完整的身份特征;最后通过多任务训练策略进一步对模型监督优化。
本文混合人脸特征提取模块采用基于Transformer架构的CvT[11]模型。CvT模型通过将卷积处理引入到Transformer的操作,使其具备了卷积神经网络(convolutional neural networks, CNN)与Transformer这两类网络架构的优点。相比于纯粹的CNN或者Transformer架构,CvT模型在提取特征信息方面性能更强,并且参数更少。本文对基于Transformer架构的 CvT 模型进行改进,移除最后的特征压缩阶段,输出大小为7×7像素的特征图,以保留更多的图像信息,避免图像压缩时某些特征消失,造成人脸识别信息缺失。
1.2 特征解耦模块
以往的研究采用线性分离方式对身份特征和年龄特征进行解耦,忽略了线性分离破坏共享特征的可能,造成某些特征缺失。为了更好地去除面部信息中冗余的年龄信息,本文提出一种新的人脸特征解耦-耦合框架,如图2所示。
初始的混合人脸特征图${X_{{\text{crude}}}} \in {{{\rm{R}}}^{C\times H\times W}}$,是由混合特征提取模块$T$从输入的图像$ I $中提取${\text{(}}{X_{{\rm{crude}}}}{\text{ = }} T(I){\text{)}}$,定义的人脸特征组成如下:
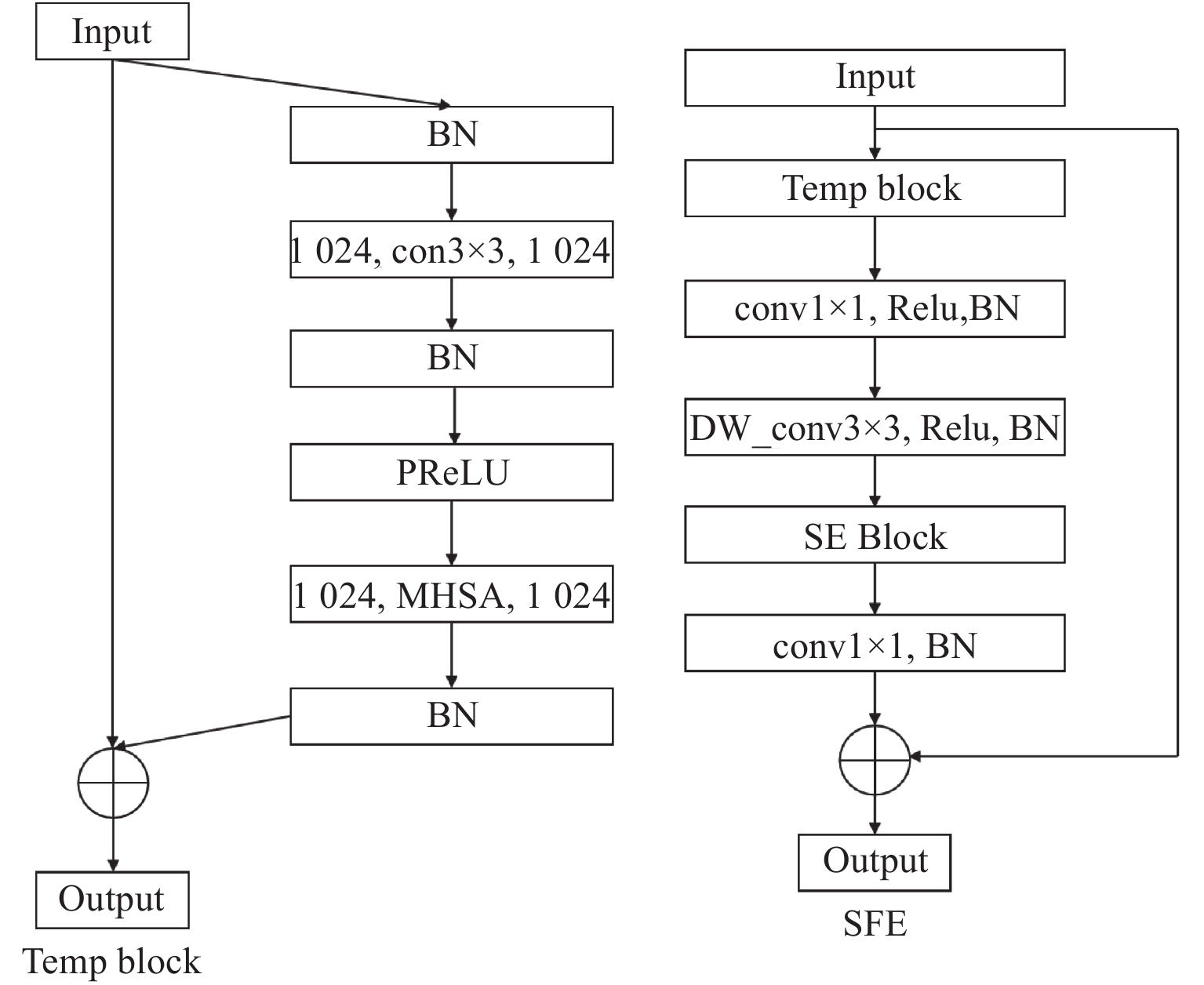
$$ {X_{{\text{crude}}}}{\text{ = }}{X_{{\text{pure\_id}}}}{\text{ + }}{X_{{\text{pure\_age}}}}{\text{ + }}{X_{{\text{shared}}}} $$ (1) 式中:${X_{{\text{pure\_id}}}}$和${X_{{\text{pure\_age}}}}$分别表示纯身份特征和纯年龄特征;${X_{{\text{shared}}}}$代表年龄和身份共享的特征。更详细地说,本文设计了一个类似文献[12]中的多头自注意卷积模块来捕捉共享特征,称为共享特征提取模块(shared feature extraction module, SFE),其结构如图3所示。将其残差部分视为可分离的身份和年龄特征,表示如下:
$$ {X_{{\text{shared}}}}{\text{ = }}M_{\rm{SFE}}{\text{(}}{X_{{\text{crude}}}}{\text{) }} $$ (2) $$ {X_{{\text{Separable}}}}{\text{ = }}{X_{{\text{crude}}}} - {X_{{\text{shared}}}} $$ (3) 接下来,利用注意力机制[9]对可分离的混合特征进一步解耦:
$$ {X_{{\text{Separable}}}}{\text{ = }}\underbrace {{\text{ }}\rho {\text{(}}{X_{{\text{Separable}}}}{\text{)}}}_{{X_{{\text{pure\_age}}}}}{{ + }}\underbrace {{X_{{\text{Separable}}}} \circ {{(1 - }}\rho {\text{(}}{X_{{\text{Separable}}}}{\text{))}}}_{{X_{{\text{pure\_id}}}}} $$ (4) 式中:$\;\rho $表示注意模块;$ \circ $代表元素级乘法。
1.3 特征耦合模块
纯身份特征和共享特征都含有身份相关信息,为了保证身份信息的完整性,在多个维度对这两种特征进行重组,得到一个完整的身份特征向量,用于最终的身份识别任务。本文设计了两种身份特征增强函数$ \varphi \text{ }和\text{ }\gamma $,对应不同维度上的共享特征,旨在增强共享特征身份信息的表达,抑制不同维度下共享特征中的年龄信息表达。依据不同的作用,本文将这两个函数分别称为初始身份增强模块(initial identity augmentation modules, IIA)和压缩身份增强模块(compressed identity augmentation modules, CIA),表示如下:
$$ {X_{{\text{initial\_id}}}} = {X_{{\text{pure\_id}}}}{\text{ + }}\varphi {\text{(}}{X_{{\text{shared}}}}{\text{)}} $$ (5) $$ {{\boldsymbol{E}}_{{\text{compressed\_id}}}}{\text{ = }}\gamma {\text{(}}{X_{{\text{shared}}}}{\text{)}} $$ (6) 式中:$\varphi $表示共享特征图部分的身份增强;$\gamma $表示共享特征向量部分的身份增强。在最后的特征向量重组阶段,本文在${X_{{\text{initial\_id}}}}$上附加一层降维线性层$C{\text{ }}$,用于身份分量监督及其后的向量重组。对于所得到的两个身份相关向量之间的重组,引入映射函数$\omega $,称之为向量重组模块(vector reorganisation module, VRM)[13],定义如下:
$$ {{\boldsymbol{E}}_{{\text{id}}}}{\text{ = }}\omega {\text{(}}{{\boldsymbol{E}}_{{\text{compressed\_id}}}}{\text{ + }}C{\text{(}}{X_{{\text{initial\_id}}}}{\text{))}} $$ (7) VRM的结构如图4所示。在最后的测试阶段,提取完整的身份特征向量${{\boldsymbol{E}}_{{\text{id}}}}$用于身份识别。
1.4 多任务训练学习框架
本文引入多任务训练策略对人脸身份特征进行监督学习,加以优化。如图1所示,监督模块存在3种基本类型:年龄鉴别器、身份鉴别器和去相关任务鉴别器。
对于年龄特征的学习,引入两个年龄鉴别器,用于共享特征和年龄特征的监督学习。严格遵循相关文献[10,14-15]中对年龄成分的做法,根据不同的年龄间隔将年龄分为8个年龄组,在获得的年龄特征上附加一个降维线性层$ F \in {\rm{R}^{1\;024 \times 8}} $,最后使用具有交叉熵损失的softmax层进行年龄分类。年龄分类任务的损失函数定义为
$$ {L_{{\text{age}}}} = {\ell _{{\text{ce}}}}(F{\text{(}}{X_{{\text{pure\_age}}}}{\text{), }}{g_{{\text{age}}}}) $$ (8) $$ {L_{{\text{shared}}\_}}_{{\text{age}}} = {\ell _{{\text{ce}}}}(F{\text{(}}{X_{{\text{shared}}}}{\text{), }}{g_{{\text{age}}}}) $$ (9) 式中:${g_{{\text{age}}}}$为真实的年龄分类组标签;${\ell _{{\text{ce}}}}$为交叉熵损失。
对于身份信息的学习,引入4个身份鉴别器,对解耦-耦合过程中的身份分量特征进行监督学习,以确保身份信息的正确性和完整性。除了最终用于身份识别的身份特征是由ArcFace[16]损失监督$(s = 64,m = 0.3)$,其他的身份特征分量都是由CosFace[17]损失$(s = 64,m = 0.35)$监督学习的。身份识别的损失函数定义如下:
$$ {L_{{\text{id}}}}{\text{ = }}{\ell _{{\text{ArcFace}}}}{\text{(}}{{\boldsymbol{E}}_{{\text{id}}}}{\text{, }}{y_{{\text{id}}}}{\text{)}} $$ (10) $$ {L_{{\text{shared\_id}}}}{\text{ = }}{\ell _{{\text{CosFace}}}}{\text{(}}C{\text{(}}X{}_{{\text{shared}}}{\text{), }}{y_{{\text{id}}}}{\text{)}} $$ (11) $$ {L_{{\text{pure\_id}}}} = {\ell _{{\text{CosFace}}}}(C({X_{{\text{pure\_id}}}}{\text{), }}{y_{{\text{id}}}}) $$ (12) $$ {L_{{\text{initial\_id}}}} = {\ell _{{\text{CosFace}}}}{\text{(}}C{\text{(}}{X_{{\text{initial\_id}}}}{\text{), }}{y_{{\text{id}}}}{\text{)}} $$ (13) 式中:${X_{{\text{shared}}}}$表示共享特征图;${X_{{\text{initial\_id}}}}$表示重组的特征图;${y_{\text{id}}}$表示身份标签;$C$表示使用降维线性层提取特征向量。
为了鼓励年龄和身份两种特征的解耦,本文对纯粹身份特征和纯粹的年龄特征之间进行相关性分析[9,15,18],以对抗的方式降低两种特征之间的潜在联系性。在相关性降低的对抗性学习中,去相关任务鉴别器即为年龄和身份之间的最大相关性:
$$ {L_{{\text{de\_correlation}}}} = {\ell _{{\text{DAL}}}}{\text{(}}{X_{{\text{pure\_id}}}}{\text{, }}{X_{{\text{pure\_age}}}}{\text{)}} $$ (14) 综上所述,在多任务学习训练框架下AIFR最终损失的公式定义为
$$ \begin{split} L =& {L_{{\text{id}}}} + {\lambda _{\text{1}}}{L_{{\text{age}}}} + {\lambda _2}{L_{{\text{de\_correlation}}}} + {\lambda _3}{L_{{\text{pure\_id}}}} +\\ &{\lambda _4}{L_{{\text{initial\_id}}}} + {\lambda _5}{L_{{\text{shared\_id}}}} + {\lambda _6}{L_{{\text{shared\_age}}}} \end{split} $$ (15) 式中:${\lambda _1}$、${\lambda _2}$、${\lambda _3}$、${\lambda _4}$、${\lambda _5}$和${\lambda _6}$是平衡这些损失的标量超参数,其大小依次设置为0.1、0.1、0.3、0.3、0.1、0.1。
2 算法验证
2.1 实验数据
本文用到的数据集如表1所示。选择MS1MV2[3]作为训练数据集,它是经过清洗后的MS-Celeb-1M数据集,包含约580万张图像以及85 742个不同的身份。测试集包括AgeDB-30[19]、CACD-VS[20]、CALFW[21]、LFW[22],测试集实例如图5所示。
表 1 本文所采用的数据集Table 1. Adopted data sets2.2 详细实施
网络架构包含:1) 主干网络 使用CvT-24网络模型,输出的特征图数量为1024,大小是7×7像素;2) 共享特征提取模块(SFE) 通过“多头自注意+卷积”从初始混合人脸特征中提取出共享特征,并将残差部分视为可分离的年龄特征和身份特征;3) 年龄鉴别器 对年龄特征堆叠2层“FC+ReLU6”,进行年龄分类;4) 身份鉴别器 只有最后一个完整的身份特征向量使用ArcFace损失监督,其余的使用CosFace损失进行监督学习;5) 初始身份增强模块(IIA) 增强共享特征图阶段的身份信息,这个模块类似于文献[23]的Inception结构;6) 压缩身份增强模块(CIA) 对共享特征向量进行身份特征增强,对压缩后的共享特征通过1层“FC + Mish[24] + Batchnorm”映射为增强的身份特征向量;7) 向量重组模块(VRM) 2个向量通过2层“FC+Mish”进行重组,重组后的向量认为是完整的身份向量;8) 去相关性任务鉴别器 将可分离的年龄特征和身份特征分别输入到FC层,得到它们各自的特征向量,然后进行去相关对抗处理。训练细节:首先将年龄分为8个不重叠的年龄组0~12、13~18、19~25、26~35、36~45、46~55、56~65岁和66+,然后根据分组年龄标签进行年龄估计任务;训练模型时,设置batch size大小为64,训练迭代次数为35轮;使用随机梯度下降法对网络模型进行优化,初始学习率设定为 0.003,在迭代次数为 5、10、15、20、25 时,学习率分别降为上一次的 0.2倍;设置momentum大小为0.9;使用1块GPU(NVIDIA V100)进行加速训练。测试环境:Python3,pytorch 1.5.1,显卡为 NVIDIA V100,CUDA 版本为 11.4。
2.3 在不同测试集上的结果
本文使用MS1MV2数据集进行模型训练,并在3个公开的人脸老化数据集 AgeDB-30、CACD-VS、CALFW和一个基准数据集LFW上进行模型测试,结果如表2所示。可以看出,本文提出的方法超过了之前关于AIFR研究的结果,识别准确率比最先进的MTLFace方法在AgeDB-30数据集上高了0.84%,在CACD-VS数据集上高了0.03%,在CALFW数据集上高了0.11%。本文提出的方法在LFW数据集上取得了99.73%的结果,证明了该方法具有很强的泛化性。不同的数据集上存在结果差异,是因为不同的跨年龄人脸测试集图片来源不同,AgeDB-30的图像采集自实际场景下的人脸,CACD-VS是来自2 000位名人的照片,CALFW是基于LFW的跨年龄数据集。光照、遮挡、姿势等因素也会对人脸识别造成干扰。
表 2 不同的方法在4个数据集上的准确率Table 2. Accuracy of different methods on four data setsAcc/% 2.4 消融实验
为进一步分析身份-年龄共享特征对跨年龄人脸识别任务的影响,在3个人脸老化数据集上进行了消融实验。1) Baseline:直接采用CvT网络提取身份特征向量进行身份识别。2) Baseline+Age:在 1) 的基础上,增加年龄估计任务,并通过联合监督年龄和身份来训练模型。3) 本文提出的ISF:使用ISF方法对3个人脸验证集进行评估。表3显示了消融实验测试的结果,在这3个数据集上性能的提升验证了本文方法的有效性。
表 3 消融实验Table 3. Ablation testAcc/% Model AgeDB-30 CACD-VS CALFW Baseline 96.23 99.14 95.27 Baseline + Age 96.25 99.18 95.30 ISF(Our) 97.07 99.58 95.73 3 结论
本文在DAL和MTLFace人脸识别的结构上,引入共享特征来避免AIFR特征分解缺陷的方法。该方法解决了使用线性分离方式解耦特征的局限,对于无法分割的特征也进行了相应的处理,提高了身份特征的完整度。提出的多鉴别器监督学习策略可以规范特征的耦合,加快模型的收敛速度。在多个数据集上的实验结果证明该方法能够显著提升跨年龄人脸识别的准确率。本文方法可以改善使用线性分离方式解耦特征的局限,扩展应用到姿态不变性、遮挡、表情等其他特征分解实例,解决类似的解耦不充分问题。
-
表 3 消融实验
Table 3 Ablation test
Acc/% Model AgeDB-30 CACD-VS CALFW Baseline 96.23 99.14 95.27 Baseline + Age 96.25 99.18 95.30 ISF(Our) 97.07 99.58 95.73  下载: 导出CSV
下载: 导出CSV
-
[1] CAO Q, SHEN L, XIE W, et al. Vggface2: A dataset for recognising faces across pose and age[C]//2018 13th IEEE international conference on automatic face & gesture recognition (FG 2018). Xi'an, China: IEEE, 2018: 67-74.
[2] 宋力争, 林冬云, 彭侠夫, 等. 基于深度学习的patch-match双目三维重建[J]. 应用光学,2022,43(3):436-443. doi: 10.5768/JAO202243.0302003 SONG Lizheng, LIN Dongyun, PENG Xiafu, et al. Patch-match binocular 3D reconstruction based on deep learning[J]. Journal of Applied Optics,2022,43(3):436-443. doi: 10.5768/JAO202243.0302003
[3] GUO Y, ZHANG L, HU Y, et al. Ms-celeb-1m: a dataset and benchmark for large-scale face recognition[C]//European conference on computer vision. Amsterdam, Netherlands: Springer, Cham, 2016: 87-102.
[4] SUN Y, CHEN Y, WANG X, et al. Deep learning face representation by joint identification-verification[J]. Advances in neural information processing systems,2014,2(12):1988-1996.
[5] TAIGMAN Y, YANG M, RANZATO M A, et al. Deepface: closing the gap to human-level performance in face verification[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Columbus, OH, USA: IEEE, 2014: 1701-1708.
[6] ANTIPOV G, BACCOUCHE M, DUGELAY J L. Face aging with conditional generative adversarial networks[C]//2017 IEEE international conference on image processing (ICIP). Piscataway, NJ: IEEE, 2017: 2089-2093.
[7] ZHANG Z, SONG Y, QI H. Age progression/regression by conditional adversarial autoencoder[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017: 5810-5818.
[8] GONG D, LI Z, LIN D, et al. Hidden factor analysis for age invariant face recognition[C]// 2013 IEEE International Conference on Computer Vision (ICCV). Piscataway, NJ: IEEE, 2013: 2872-2879.
[9] WANG H, GONG D, LI Z, et al. Decorrelated adversarial learning for age-invariant face recognition[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019: 3527-3536.
[10] HUANG Z, ZHANG J, SHAN H. When age-invariant face recognition meets face age synthesis: A multi-task learning framework[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, TN, USA: IEEE, 2021: 7282-7291.
[11] WU H, XIAO B, CODELLA N, et al. Cvt: introducing convolutions to vision transformers[C]//2021 IEEE/CVF International Conference on Computer Vision (ICCV). Montreal, QC, Canada: IEEE, 2021: 22-31.
[12] SRINIVAS A, LIN T Y, PARMAR N, et al. Bottleneck transformers for visual recognition[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, TN, USA: IEEE, 2021: 16519-16529.
[13] CAO K, RONG Y, LI C, et al. Pose-robust face recognition via deep residual equivariant mapping[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018: 5187-5196.
[14] WANG Y, GONG D, ZHOU Z, et al. Orthogonal deep features decomposition for age-invariant face recognition[C]//Proceedings of the European conference on computer vision (ECCV). Munich, Germany: Springer, Cham, 2018: 738-753.
[15] 孙文斌, 王荣, 孙连烛, 等. 基于深度学习的跨年龄人脸识别技术研究[J]. 激光与光电子学进展,2022,59(2):1-16. SUN Wenbing, WANG Rong, SUN Lianzhu, et al. Deep learning for cross-age face recorgnition[J]. Laser & Optoelectronics Progress,2022,59(2):1-16.
[16] DENG J, GUO J, XUE N, et al. Arcface: additive angular margin loss for deep face recognition[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE , 2019: 4690-4699.
[17] WANG H, WANG Y, ZHOU Z, et al. Cosface: large margin cosine loss for deep face recognition[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018: 5265-5274.
[18] 刘成, 曹良才, 靳业, 等. 一种基于Transformer的跨年龄人脸识别方法[J]. 激光与光电子进展, 2022, 60(10): 1-11. LIU Cheng, CAO Liangcai, JING Ye, et al. Transformer for age-invariant face recognition[J]. Laser & Optoelectronics Progress, 2022, 60(10): 1-11.
[19] MOSCHOGLOU S, PAPAIOANNOU A, SAGONAS C, et al. Agedb: the first manually collected, in-the-wild age database[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Honolulu, HI, USA: IEEE, 2017: 51-59.
[20] CHEN B C, CHEN C S, HSU W H. Face recognition and retrieval using cross-age reference coding with cross-age celebrity dataset[J]. IEEE Transactions on Multimedia,2015,17(6):804-815. doi: 10.1109/TMM.2015.2420374
[21] ZHENG T, DENG W, HU J. Cross-age lfw: a database for studying cross-age face recognition in unconstrained environments[EB/OL]. [2022-08-22]. https://arxiv.org/pdf/1708.08197.pdf.
[22] HUANG G B, MATTAR M, BERG T, et al. Labeled faces in the wild: a database forstudying face recognition in unconstrained environments[C]//Workshop on faces in'Real-Life'Images: detection, alignment, and recognition. Marseille, France: University of Massachusetts, Amherst, 2008: 7-49.
[23] SZEGEDY C, LIU W, JIA Y, et al. Going deeper with convolutions[C]// 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, USA: IEEE, 2015: 1-9.
[24] MISRA D. Mish: a self regularized non-monotonic neural activation function[J]. arXiv Preprint,2019,4(2):1048550.
-
期刊类型引用(0)
其他类型引用(2)


计量
- 文章访问数: 284
- HTML全文浏览量: 74
- PDF下载量: 49
- 被引次数: 2

 陕公网安备 61011302001501号
陕公网安备 61011302001501号 